Uma Proposta de Design para Composição e Geração de Arquivos CSV
Precisei fazer o download de registros do banco de dados no formato CSV (Comma-Separated Values). É uma tarefa relativamente simples de se implementar, mas procurei alguma biblioteca que já fizesse isso. Todas as que encontrei não me pareciam bem projetadas e algo me dizia que eu teria problemas de encoding. Além disso, não havia nenhuma informação de que essas bibliotecas que encontrei implementavam a RFC4180, que é a referência oficial para formato de arquivos CSV.
Procurei alguma técnica para implementar meu próprio código de geração de CSV, mas também não encontrei – é o hábito de procurar. Tudo que encontrei foram pessoas concatenando e fazendo parse de strings e manipulando arrays. Essa é a primeira coisa que qualquer desenvolvedor pensaria em fazer, mas senti falta de um design mais bem elaborado. Achei a inspiração para fazer minha API no Data Pipelane, que é uma ferramenta de exportação para CSV e Excel. Fiz a minha implementação, mas não vou compartilhar aqui porque há muitas implementações por aí. Vou apresentar as ideias que tive e o caminho que me levou à elas para te inspirar a desenvolver sua própria solução.
Minha análise foi voltada para encontrar o que seria a menor informação; a menor parte que agregaria valor ao modelo. Concluí que era o “campo” ou “coluna” em um modelo tabular, ou seja, aquilo que aparece “n” vezes em cada linha e varia de interpretação conforme a coluna. Encapsulei os campos em classes de acordo com o tipo primitivo (String, Number, Boolean, etc) e os instanciei com um factory method. Em seguida, comecei a olhar para a linha em si, pois a vi como uma coleção de campos. Sendo a linha uma coleção de campos, simplesmente criei uma classe que represente uma linha com seus “n” campos:

Figura 1 – Modelo dos campos
A vantagem da primeira parte desse modelo é o reaproveitamento dos campos para representar outras informações de mesmo tipo, pois eles encapsulam tipos primitivos. Se na sua aplicação há um tipo mais complexo que deve ser formatado para apresentação como campo, você pode definir uma classe de campo para ele e formatar a apresentação, mas isso nos leva a segunda parte do modelo.
Imagine a dificuldade de formatar o valor numérico de um campo telefone ou CPF para uma dada apresentação. Claro que essa responsabilidade poderia ficar no próprio campo, mas imaginei os campos como “guardiões” de tipos primitivos básicos, e o telefone e o CPF nada mais seriam que tipos numéricos. Para poder reaproveitar os campos, pensei em delegar a formatação da apresentação para tipos especializados. Injetar formatadores opcionais nas classes concretas de campo pensando no padrão composite e no padrão strategy pareceu uma boa ideia. Reaproveitar campos implica reaproveitar formatadores, mas também permite que façamos outras combinações de campo e formatador.
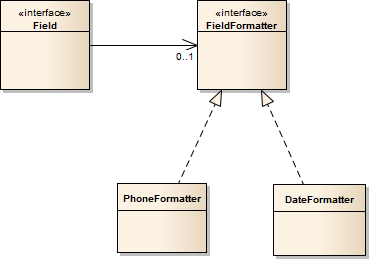
Figura 2 – Modelo dos formatadores
A última coisa que faltava nesse modelo era uma abstração para o cabeçalho da coluna, pois poderíamos querer internacionalizá-los ou fazer alguma outra formatação antes da apresentação e essa tarefa deveria ficar na classe que o encapsula:

Figura 3 – Classe que representa o cabeçalho de uma coluna
Para as colunas, poderíamos seguir a mesma linha de pensamento utilizada nos campos utilizando inclusive formatadores, mas não enxerguei essa necessidade. Para meu contexto, todas as colunas têm as mesmas características: são texto simples.
Agora que ficou definido o modelo das linhas, dos campos, dos formatadores e do cabeçalho, comecei a pensar em como juntar tudo isso para gerar o CSV. O cabeçalho deve ser escrito uma vez na saída caso seja necessário, mas as linhas devem ser escritas “n” vezes. Pensei no padrão builder para montar o CSV com o cabeçalho e as linhas. Essa abstração – que pode escrever em um arquivo, em um OutputStream, ou em outro local qualquer – deve se preocupar com o encoding e em atender a RFC4180 para compor a estrutura do CSV, ou seja, separar os campos por “,”, adicionar a quebra de linha, etc:

Figura 4 – Classes responsáveis pela criação do arquivo CSV
Conclusão
Por mais simples que seja uma implementação, nunca descuide do design, pois a manutenção corretiva e evolutiva serão prejudicadas, mas também não o valorize demais. Eu poderia ter abstraído mais esse modelo? Sim, o céu é o limite, mas devemos entender que refactoring é uma constante em desenvolvimento de software. Para não exagerar na modelagem, vale a pena ter em mente o aviso de Scott W. Ambler:
Muitas vezes, vejo desenvolvedores de software desviarem-se de suas tarefas para tentar construir um software que satisfaça às necessidades de seus usuários de um modo eficaz, com cenários tolos do tipo “o que acontecerá se…”. Eles começam a modelar demais o software para resolver todos os problemas imagináveis, com os quais os clientes dificilmente estão preocupados ou acreditam ser tão remotamente provável deles acontecerem que estariam dispostos a correr o risco. Então, por modelarem em excesso, os desenvolvedores também constroem em excesso. Sim, você não quer ser completamente simplista em seu trabalho. É razoável esperar que alguns problemas em banco de dados e falhas de rede, entre outros, realmente ocorram, mas você precisa ser realista quando estiver modelando
Referências
1. [https://northconcepts.com/blog/2012/12/10/export-csv-and-excel-from-java-web-apps-with-data-pipeline/]
2. [https://www.mkyong.com/java/how-to-export-data-to-csv-file-java/]
3. [http://viralpatel.net/blogs/java-read-write-excel-file-apache-poi/]
4. [http://www.mkyong.com/java/jexcel-api-reading-and-writing-excel-file-in-java/]
5. [http://viralpatel.net/blogs/java-read-write-csv-file/]
6. [http://zetcode.com/articles/opencsv/]
7. [https://tools.ietf.org/html/rfc4180]
8. [http://www.dofactory.com]
-
02/01/2018 às 6:02 AMComo Gerar um Arquivo XLSX com o Apache POI | Atitude Reflexiva
